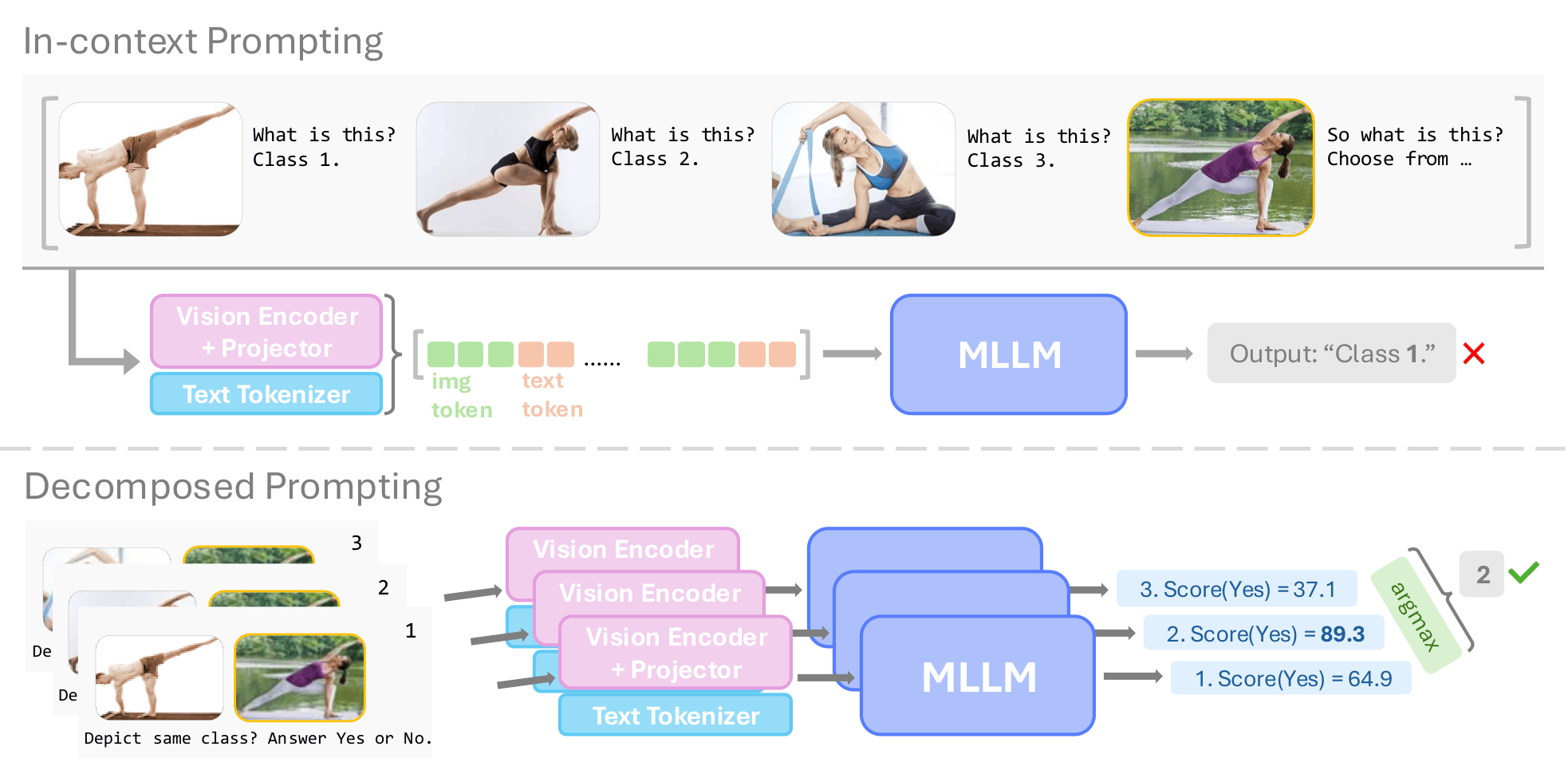
Decompose, Compare, and Decide: Multimodal LLMs are Implicit Few-Shot Learners
Yunhan Wang, Eshika Khandelwal, Edson Araujo, Walid Bousselham, Nina Shvetsova, Hilde Kuehne
European Conference on Computer Vision (ECCV) 2026
Decompose, Compare, and Decide: Multimodal LLMs are Implicit Few-Shot Learners
Yunhan Wang, Eshika Khandelwal, Edson Araujo, Walid Bousselham, Nina Shvetsova, Hilde Kuehne
European Conference on Computer Vision (ECCV) 2026
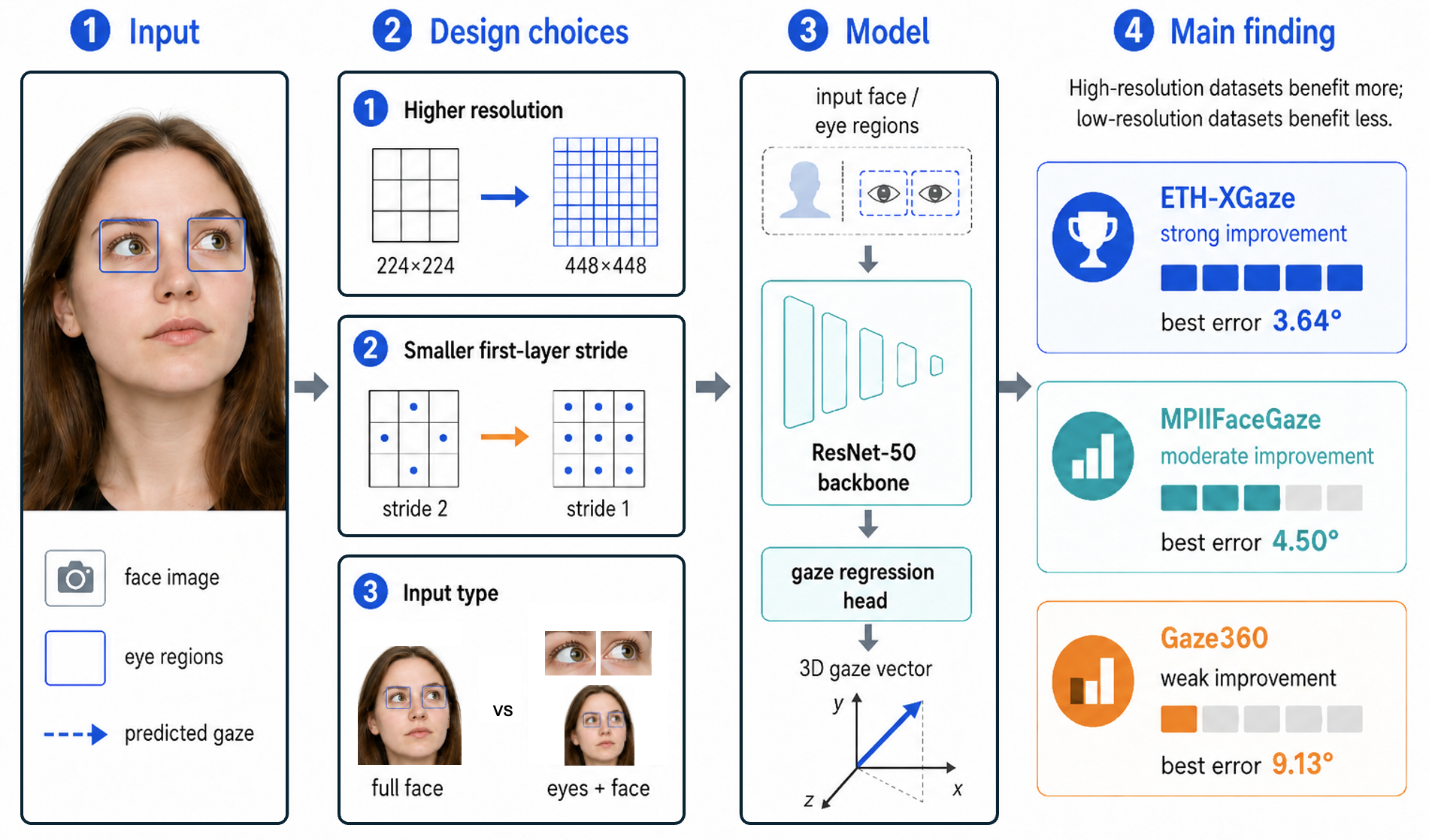
Investigation of Architectures and Receptive Fields for Appearance-based Gaze Estimation
Yunhan Wang, Xiangwei Shi, Shalini De Mello, Hyung Jin Chang, Xucong Zhang
arXiv, Technical Report 2023
Investigation of Architectures and Receptive Fields for Appearance-based Gaze Estimation
Yunhan Wang, Xiangwei Shi, Shalini De Mello, Hyung Jin Chang, Xucong Zhang
arXiv, Technical Report 2023
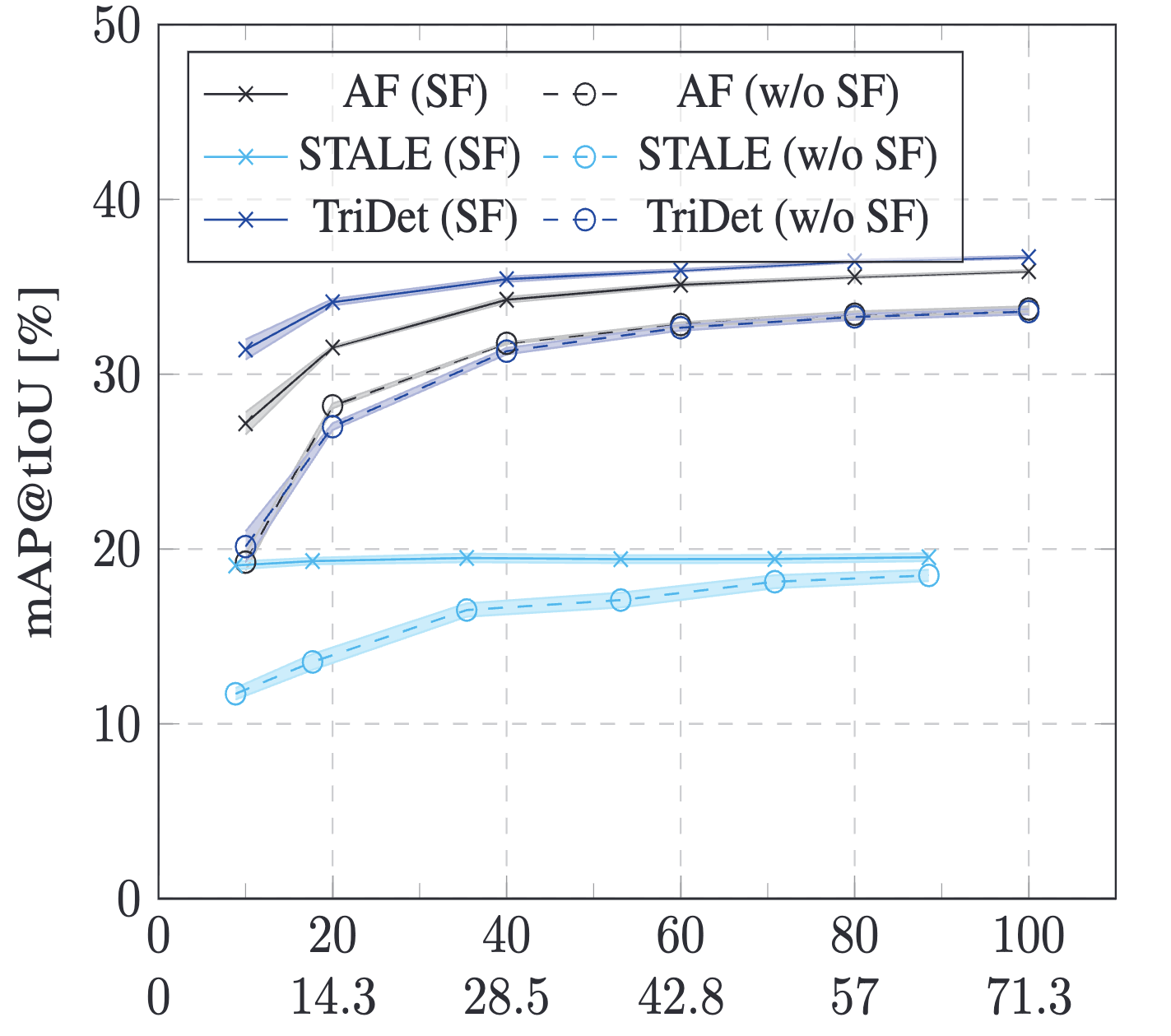
Benchmarking Data Efficiency and Computational Efficiency of Temporal Action Localization Models
Jan Warchocki*, Teodor Oprescu*, Yunhan Wang*, Alexandru Damacus, Paul Misterka, Robert-Jan Bruintjes, Attila Lengyel, Ombretta Strafforello, Jan van Gemert (* equal contribution)
CVEU @ International Conference on Computer Vision (ICCV) 2023
Benchmarking Data Efficiency and Computational Efficiency of Temporal Action Localization Models
Jan Warchocki*, Teodor Oprescu*, Yunhan Wang*, Alexandru Damacus, Paul Misterka, Robert-Jan Bruintjes, Attila Lengyel, Ombretta Strafforello, Jan van Gemert (* equal contribution)
CVEU @ International Conference on Computer Vision (ICCV) 2023